Monday, January 31, 2011
Saturday, January 29, 2011
Boxcar2d.com: Flash GA using physics
A neat site with a Flash GA algorithm. Some thoughts.
Box2d seems to be AS v3 and thus probably not compatible with Ming. Darn. So doing this easy in Declarative seems to be out. (Update: maybe not!)
The GA is irritating. Watching this, I'm thinking that first of all, always throwing the old generation away is a mistake. You get close to a good solution then you lose it. Some ways around that would be to keep the old generation around; good solutions stay there until something manages to beat them. You could vary the mutation rate according to how stagnant the solution pool seems. A larger population than 20 might be more resilient to loss, as well.
Friday, January 28, 2011
Target application: Depatenting.com
Started a new topic-specific blog for this, but it's an application of WWW::Publisher.
Great presentation of Prolog
Gotta implement this one day. Article on kuro5hin.
Leading to Learn Prolog Now.
Also, SWI-Prolog. And Building Expert Systems in Prolog.
I'd much rather have some really core stuff available in pure Perl that "does Prolog" - with the option to offload a large system into actual Prolog as necessary.
Update March 9, 2011: Kind of like AI::Prolog, for example. Oh, CPAN, is there nothing you can't find for me? Ah, yes, grist for the AI::Declarative mill....
Logic in Computer Science
Another free PDF book. I kind of wish I'd had this fifteen years ago.
Update Nov. 15, 2011: link's dead. That's a shame.
Thursday, January 27, 2011
Angular.js
Interesting library for building entire applications in JS in the browser.
Update 2013-01-16: Another mention of this from one of the guys at Kaggle: Webapps for Data Scientists
Update 2013-01-16: Another mention of this from one of the guys at Kaggle: Webapps for Data Scientists
Target application: SEO tool
It ain't hard. It could be a combination of Wx::Declarative and WWW::Declarative, plus some rules - the whole thing is already practically a declarative task right from the get-go.
A good link for SEO at SEOmoz. Some algorithmic ideas.
Startup::Declarative
OK, so where I want to go with Startup::Declarative is to paint a picture of an entire business, then allow the script to suggest things that have to be found out, planned, done, etc. Business processes, in other words.
To that end: the Process Classification Framework of the APQC. Also, open standards benchmarking assessments. These also suggest a long list of metrics and figures to be collected for a given business.
Startup::Declarative needs to be able to describe systems. The idea of System::Declarative will be to encapsulate a semantic description of various components that fit into a system. It could also define deployment, makefiles, whatever. The semantics of what exactly a "system" is are pretty vague.
Wednesday, January 26, 2011
Business model canvas
Another something that's been popular. Might be overkill to softwarize it, but ... it's part of the semantics of startups.
Target application: Pivotal Tracker
Hmm. Pivotal Tracker is a rather popular minimalist workflow manager for software (especially agile) development, and it's switching from free to paid. It honestly doesn't look terribly hard to duplicate. Here's a feature list.
Tuesday, January 25, 2011
Startup tacklebox
A venture (not yet a startup) that I've started with a couple of other guys, cataloging everything we can find about startups and how to run them, in the form of a Wiki.
What would be nice is a spider that would create and maintain a database of all the external links on that site, the date they're added and who added them, and where they appear. A manual effort to categorize them would be next. Finally, we'd try to do some kind of comparison and ranking to determine best practices for Tool X.
The first phase there is the classic textbook case of data scraping. A build-or-buy decision could result in the setting up of a scraper on ScraperWiki or the building of a hosted tool. I'm going to do both (the former for public consumption - saving time - and the latter for my own edification).
Sunday, January 23, 2011
Python generators for systems programmers
I need this in Class::Declarative! Wow! Also I need it in real life. Two birds!
Saturday, January 22, 2011
Business processes
Searching HNN for a meaningful phrase is just asking to be sent down the rabbit hole of thought. I look for business processes and find this - (TODO: think about that one for a while).
Here's what I want to do: I want to come up with an open-source set of best practices for startup business processes. Where to start?
Tuesday, January 18, 2011
Epiphany about Web publishing
I couldn't sleep last night because I was thinking so hard about Web publishing.
Best practices mandate the separation of semantics, presentation, and behavior, each of which is expressed in separate files (more or less) and in a separate language. I'd add a separation of form and content (page types as templates presenting similar types of content), and then the two additional server-side layers of the database and server-side computation - with two more languages. So we've got, in order of machine proximity (more or less): SQL, PHP/Python/Perl/Java, HTML, CSS, and JavaScript. (Plus whatever natural language is, you know, the content.)
There are sane reasons for this, primarily the fact that content writers, graphics design people, and programmers have a very, very small intersection indeed - but even in cases where, say, the programmer and graphics designer are one and the same, a separation still enhances quality: if I have a certain set of elements that I can move around and design with a graphical tool, it's far, far better to be able to isolate that in CSS and just concentrate on appearance.
But.
To do this efficiently, we need to define a set of classes (say) that CSS can grab onto, that JS can manipulate, and that HTML can key in - and those strings are arbitrary and their meaning is now spread across three files in three languages. Get me so far?
Google's JavaScript example consists of a collapsing set of menus; when I click on a menu header, JS changes a "status-on" class to a "status-off" class, and the CSS defines that as hidden or shrunk or whatever. Meanwhile, I have to remember to set things up correctly when generating the HTML, and JS has to do some trivial initialization that I can't forget to invoke on page load, either. There is a lot of coordination to do, and it's worse than that - the class attribute of things is overloaded; it both identifies items of a given class (which is what it's supposed to do) and it's used as a "shared signal" to integrate the three languages, representing the status of a given object. I'm not saying that this is wrong - I find it rather elegant - but the details are easy to miss and hard to specify correctly.
This is where a higher-level language is a real win - ideally, it would be nice to compile all three of our defining languages from a single source. (This mirrors what I had already thought about the three areas of the database, server-side code, and HTML, but bear with me - I'm still not at the epiphany.) There's only one problem: this interleaves all the stuff we've been so very careful to pull apart over the past few years.
OK, here's the epiphany. Really, kind of two.
First, we can still separate out semantics, presentation, and behavior at the object level without having to put them all into three widely separated places for the entire site. This is a far better model for the overall meaning of the things we want to present. That's kind of the lead-up epiphany, because it doesn't address the issue of specialization on the part of our creative staff.
The follow-up epiphany is that by selecting class names that are easy to key back to our object definitions, we can publish a CSS, allow a designer to modify it, then analyze the changes made in order to pull those back into our object designs. Ideally, this process would be fully automatic, but in reality there could often be a little post-hoc analysis of the changes made in order to work them into the overall design better.
This is more or less the same situation we're in when a customer marks up an existing template-generated page to represent a design, or when we do some lower-level debugging with the output of a literate programming definition. It's kind of a reversal of computation - this is not solvable in all generality, but we can certainly provide some tools for its solution.
So that's the epiphany - a high-level language that would represent Google's best Web practices. I'll follow up with some examples in a later post.
Sunday, January 16, 2011
.Less - CSS done right
Some rudimentary preprocessing of CSS directives is really all you need to organize your style sheets. .Less is one way to do that that jumped out at me months ago; not sure why I didn't mark it then. The original Ruby project is here; a .NET equivalent was at dotlesscss.com, but that seems to have succumbed to link rot now (it appears to be selling Bibles, among other things).
Best practices on the Web
I learned how to build Web things between 1994 and 1996, and kind of kept doing those same things until I switched professions in about 2004. This means that my use of HTML is incredibly naive. I've been watching Google's best-practices course (HTML, CSS, and Javascript from the Ground Up) and it's really making me think.
The key is the separation of semantics, presentation, and behavior - especially the first two. In looking at my Win32::Word::Declarative, I realize that I've hopelessly confused semantics and presentation there as well. Obviously, I need to think carefully about what I want to do there, especially in regards to tables.
I could put table headings into the column tags, for instance. The renderer would then create a row based on the column definitions. But I still don't have a clean way to define a table renderer yet. So that deserves some thought.
And then there's actual output for the Web. The Site::Declarative (that name is very tentative) module should have a reasonable page definition semantics that allows us to separate these things easily. It might even be based specifically on Google's presentation.
Food for thought.
Friday, January 14, 2011
Mojolicious
Mojolicious is a new(ish) Web framework in Perl (a case history). It occurs to me that a quickie wrapper for Mojolicious would probably be a good prototyping tool for management of other Web frameworks in any language.
Wednesday, January 12, 2011
Anonymous subroutine objects
I ran across this technique a while ago and can't remember why exactly I thought it was crucial, except that it sounds pretty neat. Anyway, a link.
Sunday, January 9, 2011
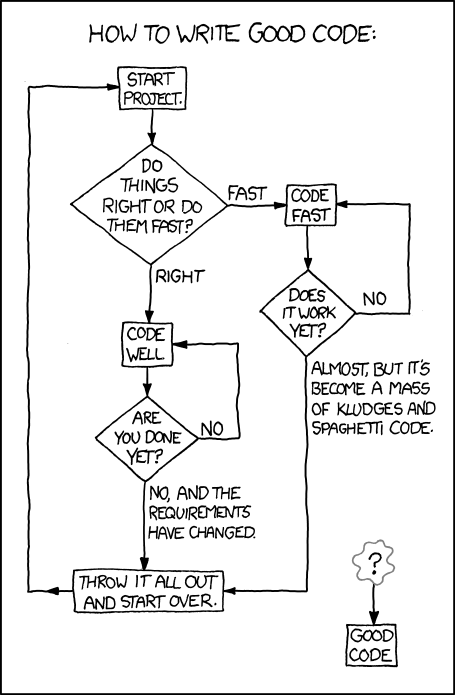
Saturday, January 8, 2011
Link dump: metaclasses in Perl
Since Class::Declarative is technically in the namespace for metaclass programming, at some point I want to be able to define classes in it. Well, and the fact that rendering of PDF content in CAM::PDF requires naming a class to do the rendering instead of proving an object - to use that system, I'm going to have to define a class.
There are other places I need to define classes; I'd like to subclass widgets in Wx, for example. All in all, it's pretty important stuff. And actually not too hard, like anything in Perl.
Class::Struct is the basic template. Essentially, you just need to generate code and run it in your caller's namespace. Here's a good article on it.
Link dump: statistics and machine learning
Mining of Massive Datasets (a book in PDF format; Stanford). HNN thread for same, with (as usual) many interesting-looking links.
Elements of Statistical Learning (another book from Stanford).
A paper on text mining in R. Not really directly interesting to me, except insofar as the basic techniques are important for any text handling system.
Programming is hard
Ha. Also, the Turkey Test. From an HNN thread about this post, which discusses this paper - and that paper is pretty interesting.
Wednesday, January 5, 2011
Research management tools
Sunday, January 2, 2011
Groups of files
Speaking of "unmunge": one logical next step will be to codify the notion of taking a group of files and doing an action on each. To do that, we're going to have to start talking about groups of files and other dynamic structure. How that's all going to play out is unclear.
Saturday, January 1, 2011
PDF internals
CAM::PDF is a pretty nice module, but as usual I've been wanting something different. So I'm back to the PDF domain, this time with a tag "pdf-internals". The internals tag is kind of different from anything I've done before, in that during payload build it goes out, finds the file specified, and then builds macro structure representing its contents.
The result, when self-described, is a readable overview of the contents of the PDF. And since the nodal structure still hooks back into the CAM::PDF::Node structure (well, it doesn't right at the moment, but you know what I mean) it ought to be relatively simple to modify and write the file back out. I haven't explored that; right now, I'm much more interested in introspection.
Reading takes place in multiple phases. First, we build the list of objects and add PDF::Declarative::InternalValue objects (which are nodes) that take whatever tag describes the type of internal value (dictionary, array, hexstring, stream, and so on). Names are the dictionary names from the PDF data structure, and labels are generally values for scalars, unused for other data types.
I'm still working on interpreting page content streams, but the idea is to locate the text strings and group them into paragraphs according to their mutual proximity and fonts. To do this, I'm going to have to develop a simple PDF command interpreter, so things are going a little slowly. But I really think it's doable, and good handling of PDFs is essential for all kinds of tasks.
I ran across a nice technical paper on PDF structure here (dated 1999, but still a great overview).
Update: The NitroPDF package does what I need to do. Of course, it's not a scripting solution, but at least it will get me what I need today, plus provide a benchmark for performance. It really munges font spacing in order to get a Word document that corresponds closely to the PDF (otherwise your text will overlap any graphical decoration). I hate that; it makes it impossible to work with TagEditor. Of course, I have my unmunge.dpl script, but still: I need something more scriptable and flexible in the long run.
Subscribe to:
Posts (Atom)